2.3. Sensors for Sorting Trash#
![]()
Probability distributions can be used to model the behavior of sensors.

How can our trash sorting system know the category of an object that enters the sorting area? Robots use sensors to measure aspects of the world, and then make inferences about the world state based on these measurements. So, sensing can be used to infer the type of the object.
Let us assume our robot cell only has three sensors:
a conductivity sensor, outputting the value
TrueorFalsea camera with a three detection algorithms: bottle, cardboard, paper
a scale, which gives a continuous value in kg.
We will discuss each in turn.
2.3.1. Binary Sensors#
A binary sensor can be modeled using conditional probability distributions.
Sadly, sensors are imperfect devices. For example, consider a sensor that measures electrical conductivity. Suppose we have a binary sensor that simply returns True or False for an object’s conductivity, based on a measurement from an electrical probe. For a metal can, this sensor will return True almost every time; however, some cans may be a bit dirty, or the probe may not make good contact, and these can lead to a misclassification, returning False.
Probability theory lets us quantify this. For example, for a metal can, the probability of the sensor returning True might be \(0.9\), and hence the probability of returning False is \(1-0.9=0.1\).
Of course in reality, we will not know the true values of these probabilities, but we can estimate them using statistics.
A straightforward approach is to merely perform a set of experiments, and construct
a histogram of the results.
Because the probability of the outcome depends on the type of the trash item, we represent this with a conditional probability, which accords a value
to every possible outcome (only True or False for this example), and where the | indicates that this depends on the category of the trash item. For example, we already established that
2.3.2. Conditional Probabilities#
In general, the probability mass function of any single variable \(X\) can be parameterized by a parameter \(Y\), whose value we assume as known. This corresponds to the notion of a conditional probability, which we write as
Note that given a particular value of \(Y\), this is just a probability distribution over \(X\), with parameters given by a PMF, as before.
There are many ways to specify conditional probabilities, but in this simple case, with a binary outcome and a finite number of discrete categories, the simplest representation is to use a a conditional probability table or CPT.
As an example, in Figure 1 we define a CPT for our binary sensor example and pretty-print it. Note the rows add up to 1.0, as each row is a valid probability mass function (PMF).
#| caption: Defining a CPT for the conductivity, given a category.
#| label: fig:ConductivityGivenCategory
pCT = gtsam.DiscreteConditional(
Conductivity, [Category], "99/1 99/1 10/90 15/85 95/5")
pretty(pCT)
P(Conductivity|Category):
| Category | false | true |
|---|---|---|
| cardboard | 0.99 | 0.01 |
| paper | 0.99 | 0.01 |
| can | 0.1 | 0.9 |
| scrap metal | 0.15 | 0.85 |
| bottle | 0.95 | 0.05 |
Conditional probability distributions are a great way to represent knowledge about the world in robotics. In particular, we use them to model sensors in this chapter. In the next chapter, we will use them to model how we can affect the state of the robot by actions.
A complete sensor model specifies a (potentially giant) CPT for every possible state. An observation \(z\) can be rather impoverished, or very detailed, and one can also envision modeling several different sensors on the robot. In the latter case, we will be able to fuse the information from multiple sensors.
Conditional probability tables do not have to be specified as giant tables, particularly if we index the discrete states with semantically meaningful indices. For example, in later chapters we will represent a robot’s workspace as a grid, and the indices into the grid can serve this purpose. In such cases, we can often specify the CPT in parametric form.
2.3.3. Multi-Valued Sensors#
Binary sensors are easily generalized to multi-valued sensors. For our running example, assume that there is a camera mounted in the work cell, looking down on the trash conveyor belt. The camera is connected to a computer which runs a vision algorithm that can output three possible detected classes: bottle , cardboard , and paper.
We can model this sensor using the conditional probability distribution
The CPT for this sensor now has three columns, and one plausible CPT is given in python code below:
pDT = gtsam.DiscreteConditional(
Detection, [Category], "2/88/10 2/20/78 33/33/34 33/33/34 95/2/3")
pretty(pDT)
P(Detection|Category):
| Category | bottle | cardboard | paper |
|---|---|---|---|
| cardboard | 0.02 | 0.88 | 0.1 |
| paper | 0.02 | 0.2 | 0.78 |
| can | 0.33 | 0.33 | 0.34 |
| scrap metal | 0.33 | 0.33 | 0.34 |
| bottle | 0.95 | 0.02 | 0.03 |
As you can tell, this detector is pretty good at detecting cardboard.
For example,
we have \(P(\text{Detection} = \text{cardboard}| \text{Category} = \text{cardboard}) = 0.88\).
Incidentally, this means that our sensor still misclassifies cardboard about 1 in 10 times, 12% to be exact, as \(1-0.88 = .12\). Unfortunately, our “vision sensor” is not great when dealing with classes it does not know about, which is rather typical of this type of model. Hence, for a metal can, the sensor essentially outputs a class at random.
2.3.4. Continuous-Valued Sensors#
Next we discuss continuous-valued sensors, like a scale, which measures an object’s weight.
For our trash sorting system, it stands to reason that the weight of an object is a good indicator of what category it might belong to, but, how should we treat continuous measurements?
We could use a very finely quantized histogram on some discretized weight scale, allowing us to use the DiscreteConditional machinery from above, but we can do much better by explicitly representing
weight as a continuous quantity.
In particular, we will not represent the probability distribution as a PMF, but will instead use a probability density function (PDF).
We will have much more to say about continuous random variable’s and PDFs later in the book, but for now we skip these details, and represent the conditional PDF for our weight sensor using the omnipresent “Bell Curve.” In particular, let us assume that we can fit a Gaussian curve to the data of a particular category. As a reminder, a Gaussian curve is defined as below:
def Gaussian(x, mu=0.0, sigma=1.0):
return np.exp(-0.5*(x-mu)**2/sigma**2)/np.sqrt(2*np.pi*sigma**2)
We can easily plot this using plotly, as shown in Figure 2.
#| caption: a Gaussian distribution with mean 250 and standard deviation 50.
#| label: fig:gaussian
X = np.arange(0, 500)
px.line(x=X, y=Gaussian(X, mu=250, sigma=50))
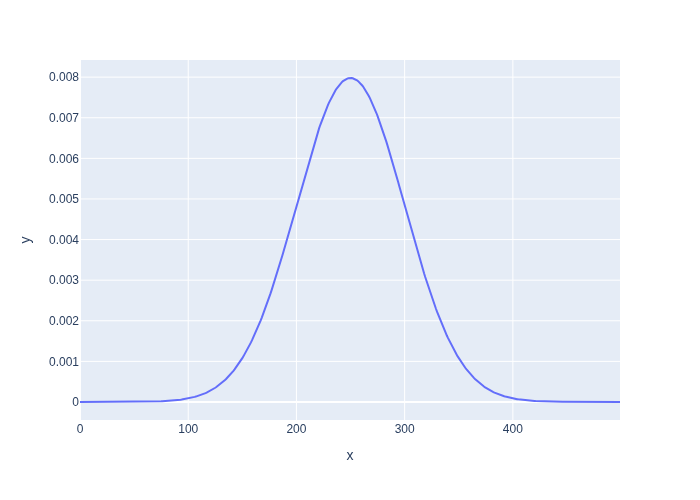
Note that for any given continuous value, the probability is zero: we can only use the Gaussian as a density, integrating over a small (or large) continuous interval to obtain the probability of the value landing within that interval.
We denote a conditional density with a lowercase \(p\) to indicate it is a density over a continuous quantity. The condition to the right of the bar is still a discrete category:
Let us assume that we fit a Gaussian to the weight of a sample of objects from every one of our 5 categories. We can represent the resulting mean and standard deviation (specified in in grams) any way we want, e.g., using a numpy array as below:
pWC = np.array([[20, 10], [5, 5], [15, 5], [150, 100], [300, 200]])
pWC
array([[ 20, 10],
[ 5, 5],
[ 15, 5],
[150, 100],
[300, 200]])
You might not remember what the 5 categories were, so Figure 2 shows a small interactive applet wherein we can change the category to see the resulting conditional density.
#| caption: The conditional density of weight given a category.
#| label: fig:weight_density
@interact(Category=categories)
def plot_weight_density(Category="can"):
index = categories.index(Category)
display(px.line(x=X, y=Gaussian(X, *pWC[index])))
2.3.5. Simulation by Sampling#
Simulation can be implemented by sampling from both state and measurement.
We can sample from a conditional distribution \(P(X|Y)\) by selecting the appropriate PMF, depending on the value of \(Y\), and proceeding as before using a method known as inverse transform sampling.
#| caption: Specifying a discrete prior for different categories.
#| label: fig:category_prior
category_prior = gtsam.DiscreteDistribution(Category, "200/300/250/200/50")
pretty(category_prior)
P(Category):
| Category | value |
|---|---|
| cardboard | 0.2 |
| paper | 0.3 |
| can | 0.25 |
| scrap metal | 0.2 |
| bottle | 0.05 |
To simulate our trash example for a single discrete sensor, we sample in two steps. We first sample from the category prior \(C\), specified in Figure 4 as in Section 2.1. We then sample from the conditional probability distribution \(P(S|C)\). Sampling from a conditional probability distribution works exactly the same way as sampling from the category prior - via the cumulative distribution function. Here we will not belabor the details again, but just use the sample method in GTSAM:
# sample from category
category = category_prior.sample()
print(f"category={category}")
# then sample from the discrete sensors
# TODO: single value
values = gtsam.DiscreteValues()
values[Category[0]] = category
print(f"conductivity = {pCT.sample(values)}")
print(f"detection = {pDT.sample(values)}")
category=0
conductivity = 0
detection = 2
Sampling from a continuous probability distribution is slightly more involved. For now, we will merely use numpy to sample from the continuous density \(p(S|C)\):
# sample from Gaussian with `numpy.random.normal`
print(f"weight = {np.random.normal(*pWC[category])}")
weight = 26.848502390857412
2.3.6. Simulating Multiple Sensors#
To simulate multiple sensors, we sample from the state, and then from each sensor. The code to do this is as follows:
# Sample from state, then from all three sensors:
def sample():
category = category_prior.sample()
values = gtsam.DiscreteValues()
values[Category[0]] = category
conductivity = pCT.sample(category)
detection = pDT.sample(category)
weight = np.random.normal(*pWC[category])
return category, conductivity, detection, weight
for _ in range(10):
print(sample())
(1, 0, 1, -8.481902421302303)
(2, 1, 1, 19.406494408312014)
(2, 1, 2, 4.184032696284206)
(1, 0, 2, 7.126372262542665)
(1, 0, 2, -1.141436024323065)
(0, 0, 1, 23.579560294040828)
(1, 0, 1, 4.840009928119474)
(1, 0, 2, 4.992004837292331)
(3, 1, 0, 377.0289458730475)
(1, 0, 2, 0.7450424039548507)
2.3.7. GTSAM 101#
The GTSAM concepts used in this section, explained.
2.3.7.1. DiscreteConditional#
Above we created an instance of the DiscreteConditional class. As with any GTSAM class, you can type
help(gtsam.DiscreteConditional)
to get documentation on its constructors and methods. In particular, we called the constructor
__init__(self: gtsam.DiscreteConditional,
key: Tuple[int, int],
parents: List[Tuple[int, int]],
spec: str) -> None
which expects three arguments (besides self, which you can ignore):
key: A tuple (id, cardinality), saying which variable this conditional is on.parents: A list of tuples, specifying the variables behind the bar.spec: A string that specifies a CPT (remember: conditional probability table) which is given as a string of PMF specifications (numbers, separated by/), in turn separated by spaces. There should be as many PMFs as there are different assignments to the parents.
We have not actually used this before, but let’s look at an example where there are two parents:
conditional = gtsam.DiscreteConditional(Category, [Conductivity, Detection],
"6/1/1/1/1 1/6/1/1/1 1/1/6/1/1 1/1/1/6/1 1/1/1/1/6 3/1/2/1/3")
pretty(conditional)
P(Category|Conductivity,Detection):
| Conductivity | Detection | cardboard | paper | can | scrap metal | bottle |
|---|---|---|---|---|---|---|
| false | bottle | 0.6 | 0.1 | 0.1 | 0.1 | 0.1 |
| false | cardboard | 0.1 | 0.6 | 0.1 | 0.1 | 0.1 |
| false | paper | 0.1 | 0.1 | 0.6 | 0.1 | 0.1 |
| true | bottle | 0.1 | 0.1 | 0.1 | 0.6 | 0.1 |
| true | cardboard | 0.1 | 0.1 | 0.1 | 0.1 | 0.6 |
| true | paper | 0.3 | 0.1 | 0.2 | 0.1 | 0.3 |
As you can see above, we had to specify six PMF groups, because there are six combinations of conductivity and detection values. The PMF specifications are read in the order that you see in the table representation above. Since conductivity is mentioned first in the parent list, it varies the slowest. It is important to pay attention to the order in which you specify conditional probability tables in this way.
We saw in Section 2.1 that GTSAM represents probability mass functions as decision trees. It should come as no surprise that GTSAM also represents discrete conditional distributions in this way, i.e., as decision trees with more than one level. For example, for the binary conductivity sensor, defined in In Figure 1, the table \(P(conductive| Category)\) is implemented by the decision tree in Figure 5. The integer labels 2 and 0 correspond to the Category and Conductivity variables, respectively.
#| caption: Decision tree for the conditional distribution $P(\text{Conductive}| \text{Category})$.
#| label: fig:decision_tree
show(pCT)

Now each PMF on the conductivity, given the category, corresponds to a small “decision stump” at the lower level of the tree, where the two leaf probabilities always add up to 1.0.
For the three-valued sensor \(P(\text{Detection}| \text{Category})\), we get the decision tree in Figure 6. Again, the decision between the 3 detections is made probabilistically at the stump level.
#| caption: Decision tree for the conditional distribution $P(\text{Detection}| \text{Category})$.
#| label: fig:decision_tree_3
show(pDT)

2.3.7.2. DiscreteValues#
Above we also used the DiscreteConditional.sample method, which takes a single argument of type DiscreteValues, specifying the actual values for the conditioning variables. Internally, this is implemented simply as a mapping from variable IDs (like Category) to values, represented as integers.
We can create a DiscreteValues instance by calling its default constructor, after which it behaves just like a Python dictionary:
values = gtsam.DiscreteValues()
pretty(values)
| Variable | value |
|---|
The key of the dictionary refers to the variable we want to assign a value to. It is an integer, so if we want to assign a value to Category, which integer key should we use? We did this with the Variables object:
VARIABLES
| Variable | Domain |
|---|---|
| Conductivity | false, true |
| Detection | bottle, cardboard, paper |
| Category | cardboard, paper, can, scrap metal, bottle |
The indices for the variables above are 0,1, and 2 respectively. So, we can just assign a value to the Conductivity variable using the index 0:
values[0] = 1
pretty(values)
| Variable | value |
|---|---|
| Conductivity | true |
Of course, we can also use the fact that the Variables.discrete method returns both the index and cardinality for the created variable, so that’s a bit more readable:
id, cardinality = Category
values[id] = categories.index("scrap metal")
pretty(values)
| Variable | value |
|---|---|
| Conductivity | true |
| Category | scrap metal |
Note that we can pretty-print it, which is nice. After creation, we can query it, again using the id:
print(values[id],
f"which corresponds to '{categories[values[id]]}'")
3 which corresponds to 'scrap metal'
2.3.7.3. Sampling#
Why does sample take a DiscreteValues? Because, if we want to sample from a conditional distribution, for example \(P(\text{Detection}| \text{Category})\), we need to specify values for the conditioning variables!
for i in range(5):
print(f"detection = {pDT.sample(values)}")
detection = 2
detection = 2
detection = 1
detection = 2
detection = 0
Check back earlier in this section to find the values for pDT and explain why you are seeing these values for “scrap metal”. You could try modifying the values variable to assign a different variable to the trash category, and confirm that sample does indeed do the right thing.